前言
在区块链模块化设计模式下,链的开发被分为以下四大主要模块:执行层、结算层、共识层、数据可用性层(DA层)。这种划分带来的明显好处是降低链开发代码的耦合性,各个模块可以专注于自己模块所负责功能的实现,通过提供接口与外部进行交互,模块替换与升级也可以做到更加丝滑。除此之外,各个模块独立的性能提升,对整体区块链的性能提升可能是倍数级别的。
对于执行层来说,传统的串行执行设计极大的限制了整体链的性能,所以基本后发的区块链都集成了并行 VM 执行引擎,其中最具代表性的方式就是:悲观执行与乐观执行。悲观执行引擎认为并发操作之间很可能发生冲突(即数据竞争和状态不一致)。在并发访问关键数据之前,先加锁(或其他方式阻塞其他并发操作),防止冲突发生。只有持有锁的线程(或事务)才能对数据进行读写操作,其他并发线程必须等待。而乐观执行则是先进行交易的执行,在交易执行期间或者结束之后进行冲突校验,如果发生数据读写冲突,再重新组织交易执行。
本文将着重介绍一下这两种并行 VM 的常见设计方式:悲观并发执行与乐观并发执行。
悲观执行
悲观执行引擎认为并发操作之间很可能发生冲突,所以在访问数据时需要加锁防止冲突发生,同时需要提前将获取锁的顺序设计好,防止出现死锁。
实现方式理解起来也比较简单:
用户在发起交易时,需要在交易中附加一个列表,该列表包含了本次交易需要访问的数据。当执行层接收到一批交易之后,根据所有交易提供的访问列表,对这些交易进行分组,组与组之间的数据访问互不冲突,而组内的交易有数据争用,需要按照一定的顺序来排。当交易分组完成后,就可以并发执行这些组的交易。而对于同组交易,可以对争用数据按顺序加锁,然后组内交易并发执行,待交易执行到争用数据时等待其他交易释放锁即可。

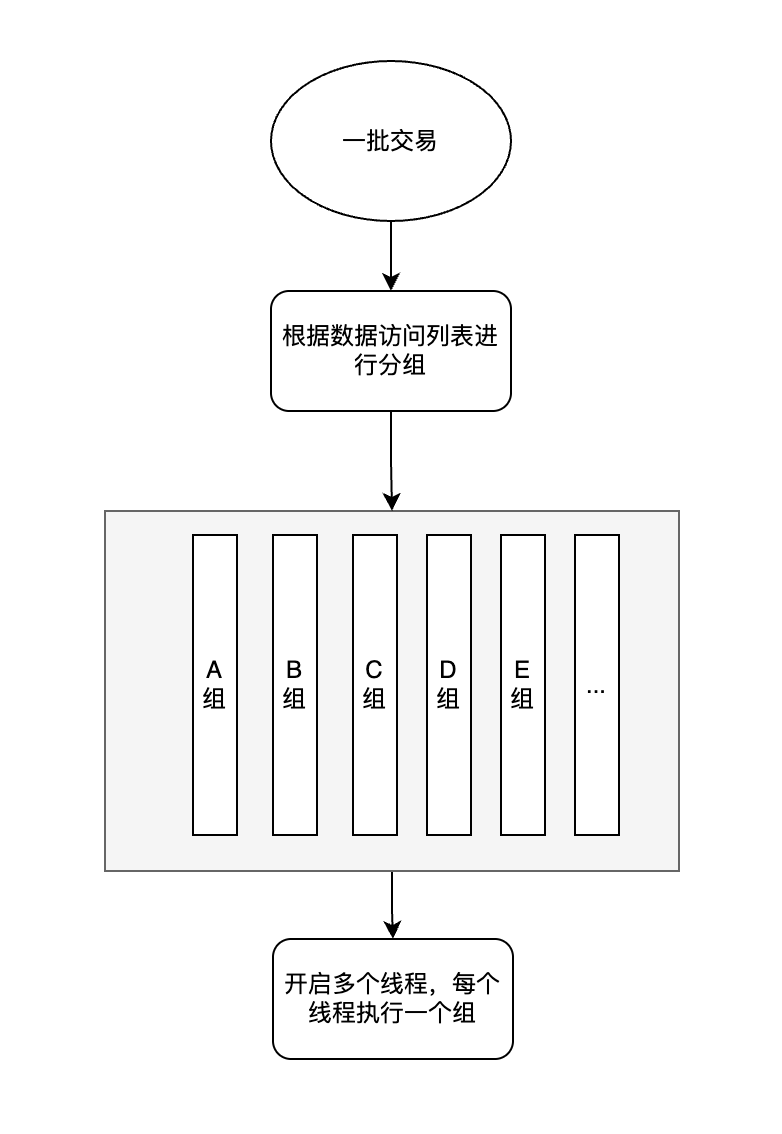
悲观执行
悲观执行引擎的实现流程是比较简单的,但是其难点在于智能合约的语言设计需要能够准确的“捕获”到交易执行时访问的数据列表,并最终给到执行层,例如 sui 使用的 move 语言。除此之外这也会增加开发者的负担,因为发送交易的时候要添加访问列表。正因为此导致其实现时无法避免的出现强耦合性,也就是说需要智能合约语言设计、账本设计等的配合才能完美实现悲观并发执行。
因为悲观并发执行的实现需要多个功能模块的配合。也就是说如果你要替换一个已有的串行 VM 引擎到悲观并发执行 VM,需要修改的功能模块会很多,所以讨论较多的并行 EVM,都是基于乐观并行的,而不是悲观并行,就是因为悲观并行对已有串行链的修改较多。
乐观执行
乐观执行则是先并行执行交易,在交易执行期间记录交易的读写数据集合,当交易执行完成后根据执行期间的读写数据集合进行数据读写冲突校验,确定是否需要重新执行交易。
下面关于乐观并发执行的介绍基于 Block-STM 论文:
Block-STM: Scaling Blockchain Execution by Turning Ordering Curse to a Performance Blessing
STM
介绍Block-STM之前,先了解下 STM(软件事务内存)。在常见的事务并发处理中会对争用的数据加锁以保证访问、修改的顺序。STM 则另辟蹊径,在执行期间不对共享数据进行加锁,而是记录事务的读写数据日志,待事务执行结束后,根据记录的读写日志做校验,如果读写的数据被争用,那么就丢弃读写日志,重新执行该事务。如果校验合法,读写的数据并未被其他事务修改,那么就根据读写日志进行数据的提交,通过此种方式避免加锁。在数据争用较少的场景下,能够获得相对于串行极大的效率提升。
Block-STM
Block-STM的输入是一个区块,区块中包含了需要按照顺序执行的一批交易 tx_1< tx_2 < tx_3 < … < tx_n,下标较小的交易先于下标较大的交易执行。Block-STM需要并行执行这些交易,并保证最终的输出(也就是写集合)需要与串行执行区块内交易获得结果一致。
与 STM 明显的区别在于,区块的执行有严格的顺序性,如果区块内的多个交易都对同一个data有修改、读取的操作,那么下标较小的执行应在下标较大的交易前面,以保证不会出现数据冲突。
Block-STM会并发执行区块内的交易,交易执行期间记录交易执行的读写集合(即在执行期间读写了那些数据),在执行结束后,会根据这些读写集合进行合法校验,校验看是否出现了数据冲突。如果出现数据冲突那么该交易将被重新执行,被重新执行的交易被称为该交易的”incarnation”,一个交易可能会被执行多次,交易第i次执行时称为该交易的第i个”incarnation”。
如下所示:
// MVHashMap 中的版本标识:(TxnIndex, Incarnation)
// incarnation从0开始
// 例如:交易5的第1次执行 = (tx_5, 0),交易5的第3次执行 = (tx_5, 2)
type Version = (TxnIndex, Incarnation);为了能够使并行的交易可以并发读写数据,Block-STM提供了一个称为MVmemory(多版本内存)的内存数据结构,该结构会记录数据对应的交易Verison=(TxnIndex, Incarnation)更新内容。该结构对于数据的读取提供并发访问,并且可根据交易Verison读取到数据的最新版本,这里读取最新版本指的是:读取小于该交易下标集合中最大下标交易更新的值。例如:tx_4交易读取 dataA,但tx_1和tx_2都更新了dataA,那么就取tx_2对应更新的data_A,而不是 tx_1 对应的。这也比较容易理解,因为相对于tx_4来说,tx_2更新的数据就是“最新”的数据。(下文中提到的读取集合也是按照此种方式读取的数据集合)。
当一个incarnation由于验证失败而中止时(后文会讲到验证的含义),多版本数据结构中对应于其写入集合的条目会被替换为特殊的 ESTIMATE 标记。这表示下一个incarnation预计会写入相同的内存位置,并用于检测潜在的依赖关系。特别是,当交易tx_j的incarnation读取由较小下标交易tx_k写入的标记为ESTIMATE的值时,tx_j会停止并等待条件变量。当tx_k的执行完成时,它会发出条件变量信号,tx_j的执行继续。这样,tx_j不会读取可能在未来由于验证失败而导致中止的值,如果tx_k的下一个incarnation确实写入相同位置的话(未被覆盖的ESTIMATE标记会被下一个incarnation移除)。
算法流程
在并行执行期间对于一个数据dataA有可能会出现以下情况:
- tx_1 读取了dataA,但是dataA此时已经被tx_2修改了。(错误执行)
- tx_1 修改了dataA(之后tx_1的执行不会再修改dataA),修改之后被tx_2读取。(正确执行)
- tx_1 修改了dataA,但在 dataA 被修改之前tx_2已经读取了dataA(错误执行)
- tx_1 修改了dataA多次,但 tx_2 在多次修改的间隙读取了dataA(错误执行)
- 出现了情况1,3,4之后,tx_3,tx_4 等也读取了 dataA,则出现了连锁依赖错误(错误执行)
我们根据以上可能出现的情况,理解以下的整个算法流程:
有两个集合E,V,集合E中放待执行的 tx incarnation,V中放待校验的tx incarnation。算法开始时会将区块内的所有交易放入E,此时V为空,之后不断从E,V中取出TX执行或校验,直至V,E都为空,算法结束。
- 调度:在V和E中选择下标较小的tx incarnation(优先执行在串行执行中应先执行的交易,以较少冲突发生的概率),进行执行或验证,执行和验证都是并行的。
- 执行:如果 tx incarnation 在执行期间读取到标记为 ESTIMATE 的数据,可以终止执行并将 tx incarnation 放入V中,同时因为可能出现连锁依赖,也需将下标大于该交易的所有交易都重新放入 V 中。也可以停止执行等待 ESTIMATE 数据更新变为非 ESTIMATE 后继续执行。
如果未读取到标记为 ESTIMATE 的数据,交易执行结束后将 tx incarnation 放入V中。执行完成后会判断 tx incarnation 执行期间输出的数据写集合 write_set 同该交易上一个 incarnation 输出的 write_set 集合是否一致,如果不一致,说明该 incarnation 执行期间出现了数据冲突,因为这里同样可能出现后续交易数据的连锁依赖,那么下标大于该交易的所有交易也都需要加入验证集合V,并将该交易 incarnation加1并放入集合E。这里需要关注一个边界情况,交易第一次执行时,如果交易有写入数据,那么说明 write_set 发生了改变,就需要将后续交易都放入验证集合 V 中。
- 校验:只校验交易执行期间从 Mvmemory 读取数据的集合 read_set,验证时会重新收集 tx incarnation对应 read_set,如果其中有数据变更那说明出现了数据冲突,则需要将该 tx incarnation加1并放入集合E去重新执行。
这里校验只需要验证读集合,因为交易是确定性的,如果读集合 read_set 不变,那么输出的写集合write_set 肯定也是不变的。 读集合一致则代表校验成功,校验成功之后交易不会放入V,E集合中。但校验成功并不意味着交易已经结束,有可能其他交易在出现校验失败的情况时,该交易会被重新拉起再次校验。
- 当V,E都为空时,算法结束。
整个算法流程图如下:
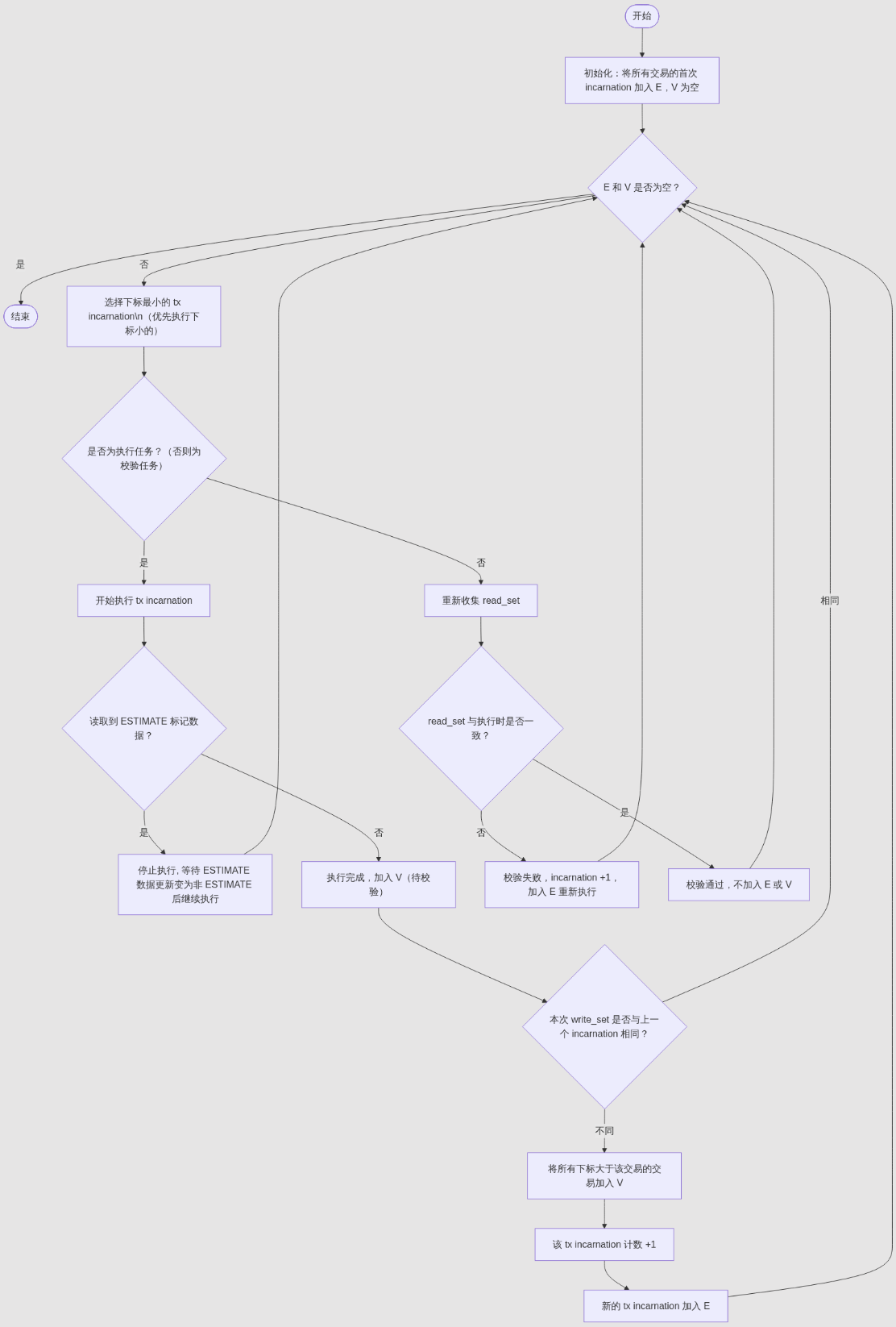

执行阶段和验证阶段有不同的关注点,执行阶段关注:"我的变化可能影响谁?","需要通知哪些交易重新验证?"。而验证阶段关注:"我依赖的数据还有效吗?""我的执行结果还正确吗?"
Block-STM的优化点
根据区块执行的特性,Block-STM在STM的基础上做出以下几点特殊优化:
- Mvmemory
提供并发的数据读取以及多版本数据的结构,为并行交易提供一个“存储”层,提升执行效率。
- ESTIMATE机制
如前文所说如果一个TX Incarnation校验失败,其写入的数据值将被标记为ESTIMATE,该交易之后的交易将被重新发起验证。同时如果其他执行中的交易读取到该ESTIMATE数据值,将会停止执行并等待,等待该标记被移除之后继续执行。
- 智能调度
优先处理低索引的交易:E,V集合中优先取低索引进行处理。
并行执行多个验证任务:同并行执行交易一样,验证任务也可并行执行。
总结
本文讲述了目前区块链并行 VM 中常用的两种做法:悲观并发执行与乐观并发执行,其中悲观并发执行需要在交易发起时附带数据访问列表,执行时根据访问列表对区块内的交易进行分组并发执行,执行的部分理解和实现相对都比较简单。但配套的例如合约语言的设计、账本的设计等需要与执行引擎密切配合。乐观并发执行则是采用 STM(软件事务内存)的设计,直接并发的执行区块内的所有交易,待发现出现数据冲突时再回滚重新执行。因为并行 vm 其对链速度的提升效果十分显著,所以当前并行 vm 已经成为链的标配。根据 Block-STM 论文给出的数据测试表现来看,当冲突较少时,并行执行的速度相比串行执行速度快 16 倍左右。目前 sui 采用是悲观并行执行引擎,aptos 采用的是乐观并行执行,由文中介绍可知悲观并行执行在相同情况下速度应该是大于等于乐观执行引擎的,但是悲观执行引擎就是需要相关配套的语言设计、账本设计等更加密切的配合,乐观执行引擎作为模块化则更加灵活。

文章评论