前言
前面文章提到的PBFT、Tendermint、Hotstuff共识算法都是BFT类的共识算法,应用到区块链当中时,共识形成的整条“链”是单一的“一条链”。而Tusk以及Bullshark是基于DAG-BFT类的共识算法(同样在3f+1个验证节点中,最多容忍f个拜占庭节点。),其形成的“链”是一个DAG(有向无环图)。
DAG-BFT类的共识的优点在于,通过将交易的传播与排序相分离,所有的验证者节点能够并行的出块,极大的提升链的TPS,以下是Bullshark论文中关于Hotstuff、Bullshark、Tusk的性能测试对比:

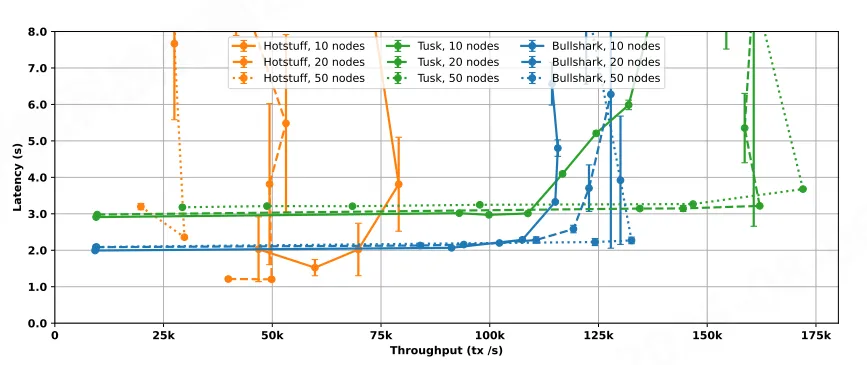
引用自文章:https://zhuanlan.zhihu.com/p/591960916(其实也是Bullshark论文给到的测试数据)
- HotStuff:在10节点、20节点和50节点共识下,吞吐量分别是70,000 tx/s、50,000 tx/s和30,000 tx/s,实验证明 HotStuff 在增加节点规模的时候扩展性不好,但是它的延迟很低,大约2秒。
- Tusk:Tusk 的吞吐量明显高于 HotStuff,对于10节点共识,其峰值为110,000 tx/s,对于20或50节点其峰值约为160,000 tx/s,吞吐量随着节点规模的增加而增加(这要得益于 DAG 的高效实现)。尽管 Tusk 的吞吐量很高,但它的延迟比 HotStuff 要高,大约为3秒。
- BullShark:BullShark 在 Tusk 的高吞吐量和 HotStuff 的低延迟之间取得了平衡。它的吞吐量也明显高于 HotStuff,在10节点和50节点共识下分别达到110,000 tx/s和130,000 tx/s,同时从图中可以观察到,无论节点规模如何,它的延迟都在2秒左右。
这里的延迟指的是用户发出交易到最终被共识处理,达到不可回退的状态的时间。
共识中的DAG
DAG(Directed Acyclic Graph)即有向无环图。如下图所示。图中的每个节点代表一个验证者打包的一批交易,这些节点通过前序的箭头指向,不断向后延展,形成一条基于DAG的“链”。

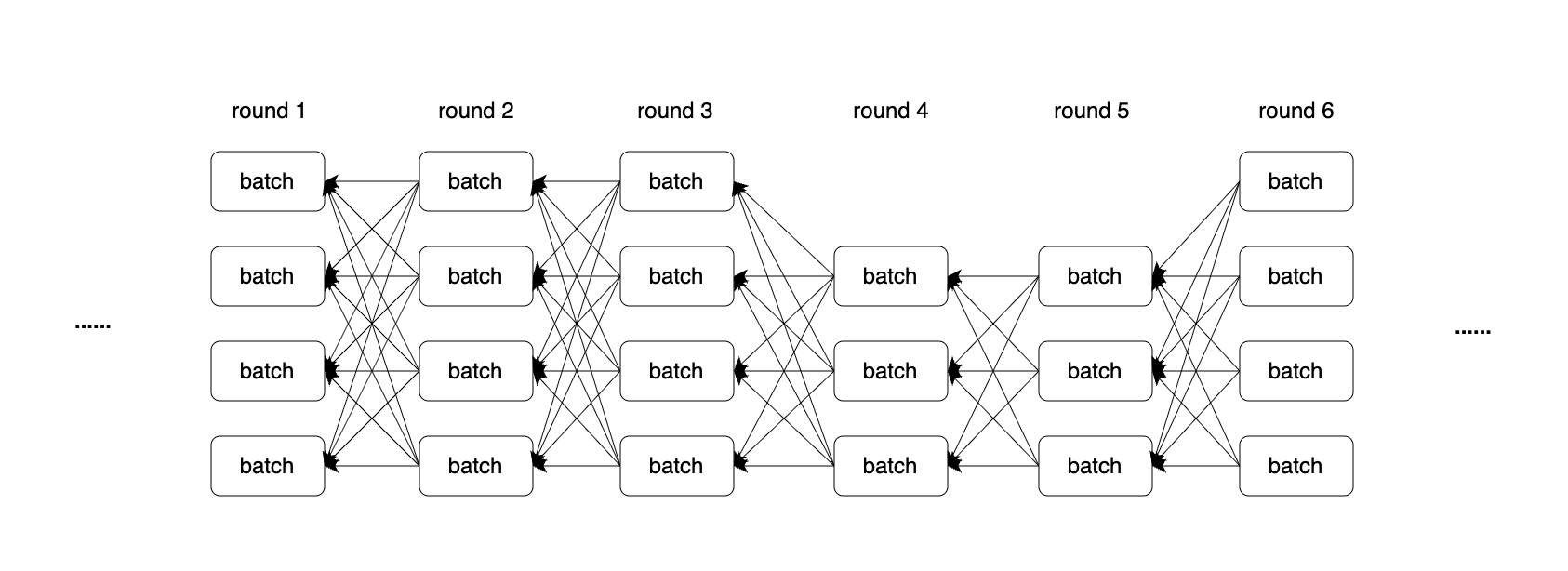
DAG-based 链
Narwhal内存池协议
共识算法在出块的时候,将该区块中包含的交易包含在共识消息中,这样随着TPS的升高,共识的信息大小会线性增长,从而降低共识算法的TPS。一个显而易见的处理方式是,在进行共识消息传递时,不传播具体的所有交易信息,而只传递待共识交易的hash,这样不仅对所共识的交易信息有了承诺,同时也避免传播大量的交易信息导致共识下降问题。这时就需要有一个“组件”专门来进行在各个共识节点间进行交易的传播,通过这种将“交易信息传播”与“共识”分离的方式,降低共识消息大小,提升共识性能。而该“组件”就是内存池协议,其目的就是收集和排序收到的交易,并在各个节点间进行同步。
协议流程
如上图所示,DAG图被划分为round(轮次),batch之间有引用关系,通过不断的对前一轮的引用,不断向后延伸。
- 收集并广播batch:用户或上层服务将交易/消息提交到本地 Narwhal mempool 节点。每个 Narwhal 节点周期性将 mempool 内交易聚合成一个“批次”(batch),每个 batch 有唯一 hash,并签名。节点将 batch 广播给所有其他节点,其他节点收到后先检查 batch hash 和签名,然后本地存储。
- Certificate 生成:当一个 batch 被超过 2f+1 个节点签名“见证”后(即达到拜占庭容错门槛),会生成一个“certificate”(即强可用性证明),证明该 batch 数据已在全网传播。类似于Tendermint、Hotstuff中的QC。
- 组织成 DAG(有向无环图):所有 batch/certificate 以 DAG 结构进行组织,每个 batch 可引用先前其他 batch(通常引用前一轮的所有 batch),这里的引用可理解为该节点接收到前一轮已经被“见证”的合法batch,这样 DAG 结构天然反映批次依赖与传播关系。当本轮接收到超过 N-f (2f+1) 个batch,就可以进入到下一轮。
- 上层共识协议读取: 如 Tusk、Bullshark、DAG-Rider 等协议只需从 Narwhal DAG 中读取已 certificate 的 batch(即已达数据可用性要求),然后对其进行排序和共识,无需关心具体交易分发细节。这里需要注意的是待共识的轮次已经接收到了至少 N-f 个batch。
关键点1:解耦DA层与共识层
验证者通过Narwhal内存池协议将客户端收集到的交易进行打包,打包的交易称为batch,然后广播出去,同时接受其他验证者发送来的batch,batch会作为一个节点放入自己本地的 DAG,每个验证者本地都会有一个batch作为节点的DAG。
上层共识协议只需负责DAG最终的排序,这样的解耦,可以使Narwhal专注于数据分发和内存池同步,能充分利用网络带宽,批量处理交易包。共识协议(如Tusk)只需对 Narwhal DAG 的摘要做排序决策,减少了通信和存储负担。
关键点2:可并发
每个验证者节点都可以参与到DAG图的构建当中,也就是说每一个验证者节点都是batch的生产者,这样就可以极大的提升链的性能。
DAG-Rider共识算法流程
讲述Tusk与BullShark之前,先介绍下DAG-Rider,DAG-Rider是较早的DAG-Based共识算法,其后的Tusk与BullShark可以看做对DAG-Rider的优化。
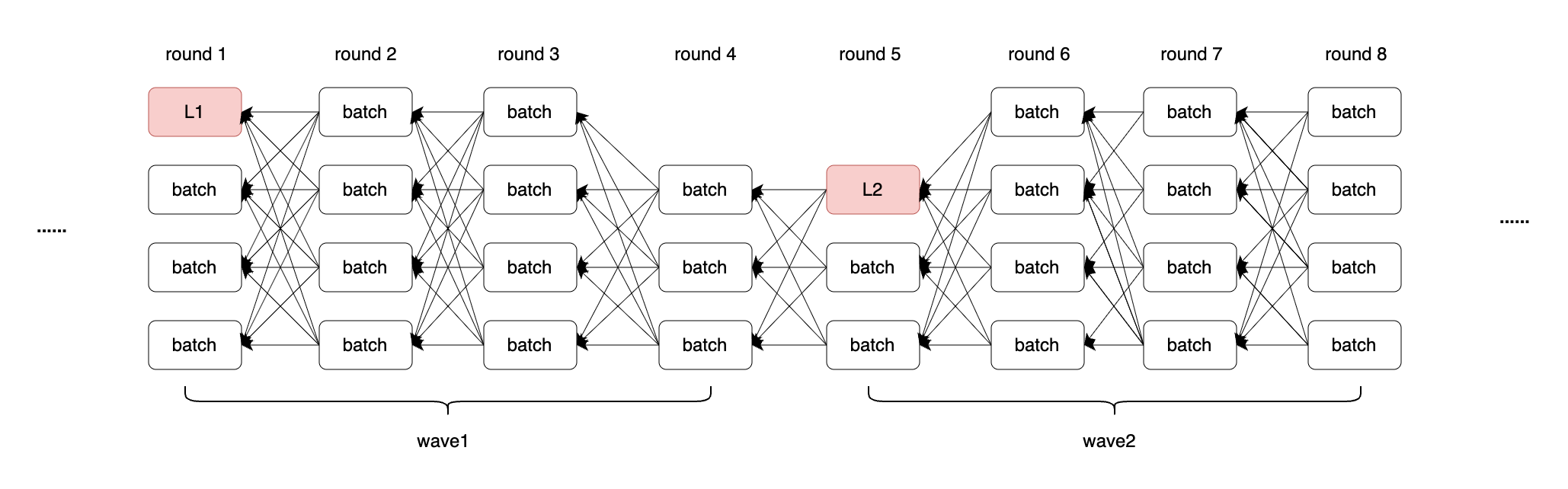

协议流程
DAG-Rider将四个round划分为一个wave(可以把wave想象成波浪,一波一波带着DAG图不断向后),每个wave的第一轮会选出一个leader batch,例如上图wave1的L1以及wave2中的L3,当进行到下一个wave的第一轮,如上图中的round5,在该轮观察上一轮,也就是round4是否有2f+1个节点可以抵达L1,如果可以抵达,就提交L1,以及L2能够追溯到的所有节点。每一个wave在第一轮都会选出来一个leader batch(各个节点之间通过算法保证每次选择出是一致的),然后在下一个wave的第一轮进行前一个wave中leader batch的判断提交。
leader batch就像是一棵大树不断延伸的主干,通过主干可以抵达所有的分支,通过leader batch。通过提交leader batch及其指向的parents batch,就串起整个DAG图连贯的不断往后延伸。
疑问点
1. 为什么2f+1个节点就足够了
因为根据内存池协议的要求,每轮至少收集 2f+1 个batch,才能推进到下一轮,所以如果在round4有2f+1个节点可以抵达round1,那么至少有一个诚实节点可以抵达L1。
2. 为什么需要四轮一个wave
我理解为类似于三次投票协议,四轮里面有三轮是用来投票的。类比Hotstuff。
3. 如果上一个leader batch提交失败呢
提交失败并不影响轮次继续向下推荐,提交下一wave leader的时候,会进行回溯,如果本轮的wave leader可以追溯到上一轮的wave leader,就会提交上一轮的leader。
Tusk共识算法流程

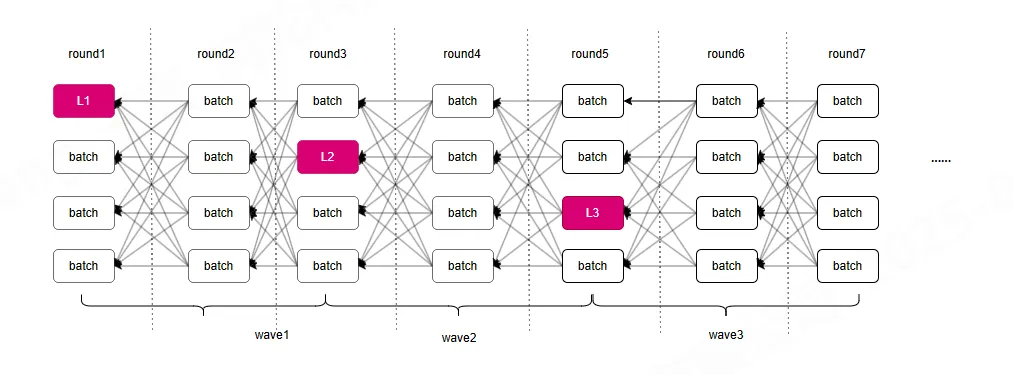
Tusk算法在DAG-Rider算法的基础上,将3轮划分为一个wave,同时每个wave的最后一个round是下一个wave的第一个round,如上图所示。也是每个wave的第一轮选择一个leader batch,该wave的最后一轮进行该leader batch提交的判断,判断的依据是leader batch的后一轮是否有f+1个节点指向leader batch。
如上图所示:
在wave1的第一轮也就是round1选择L1为leader batch,在round3时判断round2是否有f+1个batch指向L1,图中所示符合提交,即提交L1及其祖先batch。
疑问点
1. 为什么f+1个节点指向L1就可以向下了
不同于DAG-Rider,是四轮提交一个节点,而这里是三轮,r轮Leader batch需要被r+1轮 f+1 个batch引用,至少有一个诚实节点是指向 Leader batch 的。
BullShark共识算法流程
协议流程
BullShark共识算法分为异步和同步两种,异步理解起来较为复杂,同步理解实现都较为简单。
异步
与DAG-Rider类似,也是四个round划分为一个wave。BullShark 每个 wave 会有2个被称为steady-state leader(理解为主干),两个steady-state leader分别在每个wave的第一轮和第三轮,除此外每个wave还有一个fallback节点(理解为后备leader),也在每个wave的第一轮,所有验证者会根据相同的随机算法进行fallback节点的选择。除此外BullShark 还会对每个wave做一个投票类型的划分,分为steady 类型 或者 fallback 类型。
对于某个验证者,BullShark会在每个wave的第一轮和第三轮进行DAG中节点的处理。
第一轮的处理:
在本wave 第1 round,验证者在本地的DAG视图中会尝试提交 wave-1 的第2个steady-state leader(在wave-1的第3 round)。如果提交失败,会继续尝试提交 wave-1 的fallback节点(在wave-1的第1 round),如果其中的一个提交成功,那么就设置本wave投票类型为 steady 类型。否则就设置为 fallback 类型。
第三轮的处理:
在本wave 第3 round,验证者在本地的DAG视图中会尝试提交该wave的第一个steady-state leader。但如果该wave已经处于 fallback 类型,那么steady-state leader是无法提交的。对于第一轮的处理也是相同的,如果该wave已经处于fallback类型,那么无法提交 steady-state leader,只能提交 fallback 节点。类似的如果wave已经处于fallback类型,那么就无法提交fallback节点。
这里可以看出BullShark正常情况,两轮即可成功提交节点。异常情况下通过fallbcak节点来保持活性。
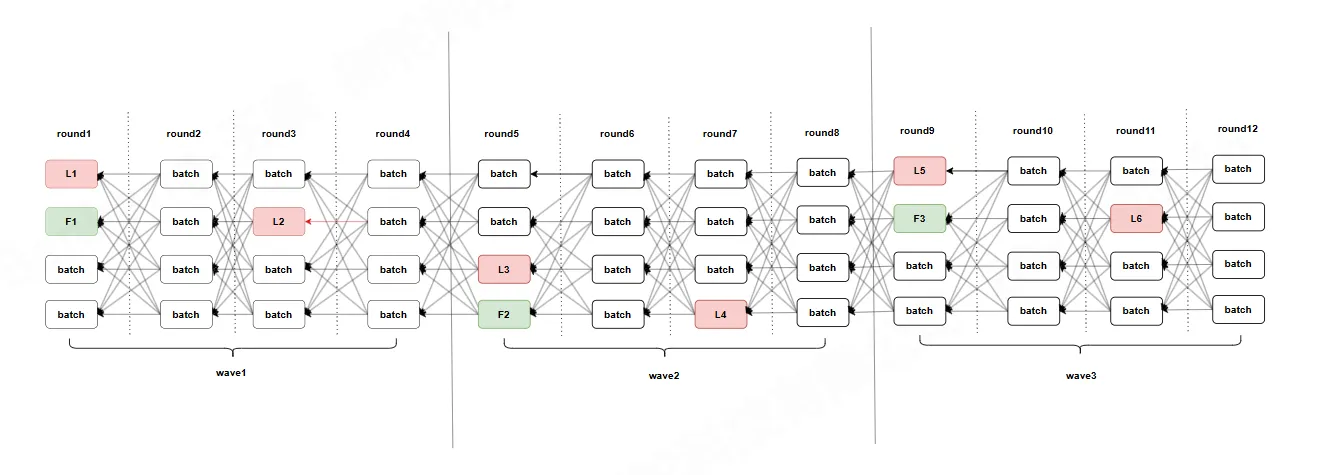

如上图所示:
- 我们假设wave1是steady类型,在wave1中,我们在round3提交round1中的L1(steady-state leader),在round2有2f+1个batch引用了L1,满足条件,进行提交。
- 在wave2的第一轮也就是round5的时候,首先尝试提交round3的steady-state leader,不满足条件提交失败,继续尝试提交round1的fallback节点,因为wave1是steady类型,所以提交失败。wave2被标记为fallback类型。
- 在wave2的第三轮也就是round7时,我们尝试提交round5的steady-state leader,因为wave2已经被标记为fallback类型,所以无法提交。
- 在wave3的第一轮round9,我们尝试提交round7的steady-state leader,同样因为wave2已经被标记为fallback类型,所以无法提交。接着尝试提交round5的fallback节点F2,满足条件,提交成功, 顺着F2递归往上找寻可提交的节点。L2只有一个引用,不满足提交,所以不提交,L1有至少f+1个引用,可以提交。
疑问点
1. 如何保证所有验证节点的投票类型一致
因为根据内存池协议的要求,每轮至少收集 2f+1 个batch,所以本地验证者只需要观察收到的2f+1个batch的引用情况,又因为leader节点直接提交需要满足2f+1个引用才能提交(fallback节点也是一样),所以就可以保证所有验证节点在该wave投票类型的一致。
2. 为什么wave被设置为fallback节点后,要跳过wave的第三轮,到下一个wave的第一轮,才能提交上一轮的fallback节点?
我理解这里就是直接退化到DAG-Rider处理的方式。
同步
同步版本的提交相对比较简单,在奇数轮设置一个leader,如果在奇数轮的小一轮,上一轮的leader获得f+1个引用,那么就提交该节点。同样的,提交某个节点之后,会回溯其parent节点,查看是否有可以提交的。
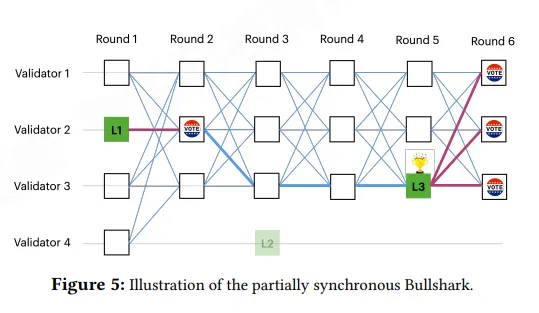

如图所示:
在round2时,L1没有获得round2 f+1节点的引用,不能提交。到round4时,观察L2没有获得round3 f+1的引用,不能提交,到round6,观察到L3获得round6 f+1个节点的引用,就提交L3。然后顺藤摸瓜可以抵达L1,就提交L1,无法抵达L2,所以不能提交。
总结
- DAG-Rider 是相对较早的DAG-Based共识算法,需要四轮安全共识,为之后的其他算法做了铺垫。
- Tusk 需要三轮提交leader batch,相对于DAG-Rider提升了提交速度。
- BullShark 在异步模式下可以做到两轮一提交,但是分出了 steady-state leader 和 fallback leader 以增加协议活性,如果两轮提交不了steady-state leader,后面就看能否提交 fallback leader。同步情况下两轮一提交,简单,容易实现,也是sui代码中关于Bullshark代码实现的选择。
这里关于Narwhal及DAG-Based算法梳理了很长时间,资料也比较少,理解起来也比较困难,所以可能会有一些错误存在,如果在阅读期间发现问题,可以在评论区抛出来,大家一起讨论学习。
其他
写到这里,对共识算法的理论学习梳理算是告一段落,共识算法是链开发当中的重点,也是决定链TPS上限的一个关键点,虽然理论理解起来比较吃力,但其整个的发展过程却有迹可循,从传统的PBFT算法,再到优化的Tendermint,再到Hotstuff,再到内存池协议,Narwhal+Tusk,这些共识算法之间联系密切,新的算法不断在之前的算法基础上优化进步,TPS不断提升。这也是整个“共识算法理解系列”的梳理逻辑,通过从最开始的PBFT共识算法开始,通过对比新的共识算法对之前算法的优化点,不断进化到如今的Narwhal+Tusk共识算法,最近sui又推出了自己新的共识算法Mysticeti,其测试数据比Narwhal+Tusk更加优异,该算法也是基于Tusk进行优化,当然这里并不是讲孰优孰略,各个共识算法的应用场景和链发展的方向是密切相关的。
所以共识算法学习的重点就是对比不同共识算法的异同点,创新点,看它们是如何一步一步向前演进!

文章评论