什么是PBFT共识算法
PBFT 是 Practical Byzantine Fault Tolerance 的缩写,翻译为拜占庭容错算法。该算法是 Miguel Castro (卡斯特罗) 和 Barbara Liskov(利斯科夫)在 1999 年提出来的,论文见:http://pmg.csail.mit.edu/papers/osdi99.pdf ,该算法解决了原始拜占庭容错算法效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行。
在区块链当中,囿于其O(n^2)的消息通信复杂度,目前直接采用PBFT作为共识算法的大多是一些联盟链,因为这些场景下节点数量有限且身份可信。其余的公链项目更多是使用PBFT的变种、改进版本或者基于PBFT思想的共识协议,以解决规模和去中心化问题。但PBFT作为共识协议的“始祖”,学习该共识算法对之后学习其他PBFT的变种共识算法十分有益。
PBFT共识算法流程
共识流程
假设有n=3f+1个节点,最多允许 f 个节点出现拜占庭故障(恶意节点或者宕机节点等),其中有一个节点是leader节点,该节点可以通过固定选择、轮询等方式获得。
PBFT算法主要通过三个步骤pre-prepare、prepare、commit三个阶段达成共识:
- request:客户端向主节点(其中一个共识节点)发起共识请求
- pre-prepare:主节点收到客户端请求后,生成一个包含请求和视图编号(view number)的预准备消息(Pre-Prepare),并将该消息广播给所有备份节点(Backup)。
- prepare:备份节点收到预准备消息后,验证消息合法性,确认主节点没有作弊,然后广播准备消息(Prepare)给所有节点,表明已准备好执行该请求。
- commit:当节点收到来自至少 2f 个不同节点的准备消息时,广播提交消息(Commit),表示准备正式提交该操作。
- reply:当节点收到至少 2f+1 个提交消息后,执行客户端请求操作,并将结果返回客户端。
这里的视图(view)与主节点相关,相当于一个主节点的任期,如果主节点出现故障,会更新主节点进行view-change操作。
如下图所示:
假设有4=3f+1=3*1+1个节点(最多容忍1个拜占庭节点)和一个客户端 C,其中0号节点是leader节点。3号节点是拜占庭节点。
- request:客户端C向0号节点发起共识请求
- pre-prepare:0 号节点向1、2、3号节点发起包含请求和视图编号的预准备消息。
- prepare:1,2,3 号节点收到消息后,先验证消息合法性,然后开始向其余节点(包括0号节点)广播prepare消息。这里3号节点出错,所以没有进行消息广播。
- commit:当0,1,2号节点收到至少2f=2*1个不同节点的prepare消息时,会向其余节点广播commit消息,表示正式提交。
- reply:0,1,2号节点收到至少2f+1个commit消息后,执行对应操作(达成共识,写入区块信息等),并将执行结果返回给客户端C。客户端收到至少 f+1 个节点的执行结果,确认操作成功。
如下图所示:
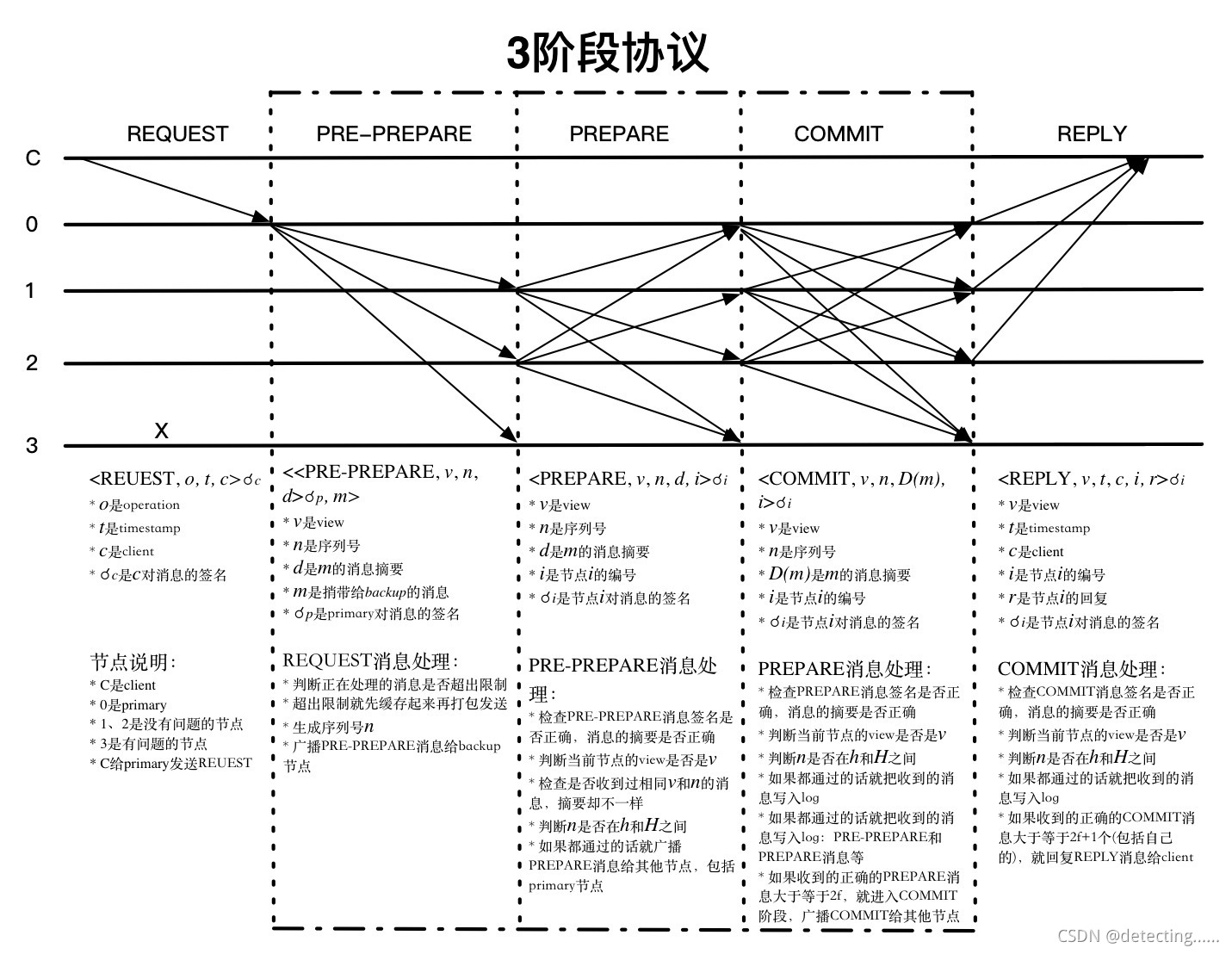

图片来源:https://blog.csdn.net/weixin_43867940/article/details/121361787
View-Chanage(视图切换)
视图(View)是指当前主节点的任期或轮次。主节点负责发起请求的排序和广播。如果主节点出现故障(如崩溃、恶意行为、网络分区),系统需要切换到新的视图,选出新的主节点,保证系统继续正常运行和达成共识。
假设当前视图编号为 v 需要切换到 v+1。
- 发送View-Change消息
每个检测到主节点失效的节点 i 向所有节点广播 View-Change(v+1) 消息。
消息中包含:
-
- 已执行的最新序号 h(即该节点认为已安全执行的最大请求序号)。
- 该节点在视图 v 下的Prepare和Commit证明(Prepare和Commit消息集合),用于证明自己执行到的状态。
这些信息用于证明节点的状态,帮助新主节点恢复一致的日志。
- 收集View-Change消息
新视图主节点(节点编号由 v+1modn 确定)收集至少 2f+1 个不同节点的View-Change消息。
通过这些消息,新主节点知道了大多数节点认可的最新安全状态,避免丢失已确认的请求。 - 发送New-View消息
新主节点将收集到的View-Change消息整理成一个 New-View(v+1) 消息,广播给所有节点。
New-View消息包括:
-
- 新视图编号 v+1。用于证明的View-Change消息集合。
- 新主节点根据收集到的状态选择的请求序列(pending requests)。
新视图中的所有节点据此恢复状态,继续共识。
- 节点确认新视图
节点收到New-View消息的节点:
-
- 验证消息的合法性和证明。
- 恢复日志和状态,保证已执行请求不被回滚。
- 开始接受新视图主节点发来的Pre-Prepare消息,进入正常共识流程。
PBFT共识算法各个阶段解释
- request:触发共识开始。
- pre-prepare 与 prepare:确保所有节点对需要共识的内容先达成一致。
- commit:确保超2/3的节点对共识的内容成功提交。
- reply:客户端确认请求已被处理。
PBFT算法中的关键点
为什么最多只能容忍 f 个恶意节点
因为拜占庭节点不仅包括恶意节点,还包含可能得宕机节点、网络异常节点等等。有可能会出现恶意节点是f个,宕机及网络异常节点f个,那诚实节点数量必须要大于恶意节点数量,所以至少是 f+1 个诚实节点。
是否可以合并pre-prepare、prepare?
Pre-Prepare和Prepare分开,是PBFT协议防止“恶意主节点作恶”和保障“请求顺序与内容一致性”的核心机制。合并两个阶段后,主节点的权力过大,缺少备份节点之间的相互验证,会导致拜占庭节点能更容易地诱导系统分裂或不一致。
例如:
主节点向一半的节点发送待共识的消息R1,另一半的节点发送待共识的消息R2,如果两个阶段合并,那么节点就带着不同的消息请求,直接进入了commit阶段。
是否可以去掉commit阶段?
commit阶段用来保证即使出现view-change,节点中也不会出现共识数据的“二义性”。
例如:当没有commit阶段时。假设有 2f+1 个节点都收到了prepare <n,m> (n表示序列号,m表示待共识的信息),那么就可以直接进行reply。这时假设其余 f 个节点因为网络问题没有收到prepare的消息,超时之后进行view-change(进行view-change时无法接受其他信息)。新选出的主节点重放<n,m>,那么对于进行view-change的f个节点来说,之前的n已经对应了view-change的消息,这样就出现了不一致的情况。
这里主要避免的是当出现试图切换时可能出现的共识分叉问题。
为什么客户端只需要收到 f+1 个节点的执行结果?
能收到消息说明已经有2f+1个节点已经达到了commited的状态,假设有f+1个reley消息的节点中有 f 个拜占庭节点,那也肯定有1个节点是正确的reley。所以至少需要f+1个。
PBFT的简单代码实现
来自AI,供学习使用
import threadingimport timefrom collections import defaultdict# 常量F = 1 # 容忍拜占庭节点数N = 3 * F + 1 # 节点总数# 消息类型定义PRE_PREPARE = 'PRE-PREPARE'PREPARE = 'PREPARE'COMMIT = 'COMMIT'VIEW_CHANGE = 'VIEW-CHANGE'NEW_VIEW = 'NEW-VIEW'# 超时时间(秒)TIMEOUT = 5class Message: def __init__(self, msg_type, view, seq_num, digest, sender, data=None): self.msg_type= msg_type self.view= view self.seq_num= seq_num self.digest= digest # 请求摘要 self.sender= sender self.data= dataclass Node: def __init__(self, node_id, network): self.node_id= node_id self.network= network self.view= 0 self.primary_id= self.view % N self.message_log= defaultdict(list) # seq_num -> list of messages self.prepared= set() # seq_num 已准备 self.committed= set() # seq_num 已提交 self.last_executed= 0 # 已执行最大序号 self.request_queue= [] # 等待执行的请求 # 报文的Prepare和Commit计数 self.prepares= defaultdict(set) # seq_num -> set(node_id) self.commits= defaultdict(set) # seq_num -> set(node_id) # View change相关 self.view_change_msgs= dict() # view -> {node_id: view-change message} self.new_view_msg= None # 超时计时器 self.timer= None self.timer_lock= threading.Lock() self.reset_timer() # 状态锁 self.lock= threading.Lock() def reset_timer(self): with self.timer_lock: if self.timer: self.timer.cancel() self.timer= threading.Timer(TIMEOUT, self.start_view_change) self.timer.start() def start_view_change(self): with self.lock: print(f"[{self.node_id}] Timeout in view {self.view}, start view change") self.view += 1 self.primary_id= self.view % N # 发送View-Change消息 vc_msg= Message( msg_type=VIEW_CHANGE, view=self.view, seq_num=self.last_executed, digest=None, sender=self.node_id, data={ 'last_executed': self.last_executed, 'prepared': list(self.prepared) } ) self.network.broadcast(self.node_id, vc_msg) def receive_message(self, msg: Message): with self.lock: # 重置超时计时器,说明主节点活跃 self.reset_timer() if msg.view < self.view: # 过时消息忽略 return if msg.view > self.view: # 进入更高视图 self.view= msg.view self.primary_id= self.view % N self.view_change_msgs.clear() self.new_view_msg= None if msg.msg_type == PRE_PREPARE: self.handle_pre_prepare(msg) elif msg.msg_type == PREPARE: self.handle_prepare(msg) elif msg.msg_type == COMMIT: self.handle_commit(msg) elif msg.msg_type == VIEW_CHANGE: self.handle_view_change(msg) elif msg.msg_type == NEW_VIEW: self.handle_new_view(msg) def handle_pre_prepare(self, msg: Message): if self.node_id == self.primary_id: # 主节点不处理自己的Pre-Prepare消息 return # 记录Pre-Prepare self.message_log[msg.seq_num].append(msg) print(f"[{self.node_id}] Received PRE-PREPARE view={msg.view} seq={msg.seq_num} from {msg.sender}") # 发送Prepare消息 prepare_msg= Message( msg_type=PREPARE, view=msg.view, seq_num=msg.seq_num, digest=msg.digest, sender=self.node_id ) self.network.broadcast(self.node_id, prepare_msg) def handle_prepare(self, msg: Message): # 统计Prepare消息 self.prepares[msg.seq_num].add(msg.sender) count= len(self.prepares[msg.seq_num]) print(f"[{self.node_id}] Prepare count for seq {msg.seq_num}: {count}") if count >= 2 * F and msg.seq_num not in self.prepared: self.prepared.add(msg.seq_num) print(f"[{self.node_id}] Prepared seq {msg.seq_num}") # 发送Commit消息 commit_msg= Message( msg_type=COMMIT, view=msg.view, seq_num=msg.seq_num, digest=msg.digest, sender=self.node_id ) self.network.broadcast(self.node_id, commit_msg) def handle_commit(self, msg: Message): # 统计Commit消息 self.commits[msg.seq_num].add(msg.sender) count= len(self.commits[msg.seq_num]) print(f"[{self.node_id}] Commit count for seq {msg.seq_num}: {count}") if count >= 2 * F + 1 and msg.seq_num not in self.committed: self.committed.add(msg.seq_num) print(f"[{self.node_id}] Committed seq {msg.seq_num}") # 执行请求(简单模拟) if msg.seq_num == self.last_executed + 1: self.execute_request(msg.seq_num) else: # 排序执行,加入队列 self.request_queue.append(msg.seq_num) self.request_queue.sort() # 重置计时器,已处理请求视为活跃 self.reset_timer() def execute_request(self, seq_num): print(f"[{self.node_id}] Execute request with seq {seq_num}") self.last_executed= seq_num # 执行队列中可执行的请求 while self.request_queue and self.request_queue[0] == self.last_executed + 1: next_seq= self.request_queue.pop(0) print(f"[{self.node_id}] Execute queued request {next_seq}") self.last_executed= next_seq def handle_view_change(self, msg: Message): print(f"[{self.node_id}] Received VIEW-CHANGE for view {msg.view} from {msg.sender}") if msg.view not in self.view_change_msgs: self.view_change_msgs[msg.view] = {} self.view_change_msgs[msg.view][msg.sender] = msg msgs= self.view_change_msgs[msg.view] if len(msgs) >= 2 * F + 1 and self.node_id == self.primary_id and self.new_view_msg is None: # 新主节点收集足够View-Change消息,发送New-View new_view_msg= Message( msg_type=NEW_VIEW, view=msg.view, seq_num=0, digest=None, sender=self.node_id, data={ 'view_changes': msgs } ) print(f"[{self.node_id}] Broadcast NEW-VIEW for view {msg.view}") self.new_view_msg= new_view_msg self.network.broadcast(self.node_id, new_view_msg) def handle_new_view(self, msg: Message): print(f"[{self.node_id}] Received NEW-VIEW for view {msg.view} from {msg.sender}") if msg.view >= self.view: self.view= msg.view self.primary_id= self.view % N self.view_change_msgs.clear() self.new_view_msg= msg # 状态恢复,略(可扩展) self.reset_timer() # 主节点收到客户端请求,发起共识 def receive_client_request(self, seq_num, digest): if self.node_id != self.primary_id: print(f"[{self.node_id}] Not primary, ignore client request") return print(f"[{self.node_id}] Primary receive client request seq={seq_num}") # 发送Pre-Prepare消息 msg= Message( msg_type=PRE_PREPARE, view=self.view, seq_num=seq_num, digest=digest, sender=self.node_id ) self.message_log[seq_num].append(msg) self.network.broadcast(self.node_id, msg)class Network: def __init__(self): self.nodes= {} self.lock= threading.Lock() def add_node(self, node: Node): with self.lock: self.nodes[node.node_id] = node def broadcast(self, sender_id, msg: Message): with self.lock: for node_id, node in self.nodes.items(): # 主动跳过发消息给自己以外的节点 if node_id != sender_id: # 模拟网络延迟 threading.Thread(target=node.receive_message, args=(msg,)).start() def main(): network= Network() nodes= [Node(i, network) for i in range(N)] for node in nodes: network.add_node(node) # 模拟客户端发请求(seq从1开始) def client_simulation(): seq= 1 while True: primary= nodes[seq % N] # 轮换主节点模拟 primary.receive_client_request(seq_num=seq, digest=f"request-{seq}") seq += 1 time.sleep(3) client_thread= threading.Thread(target=client_simulation) client_thread.daemon= True client_thread.start() # 主程序阻塞,观察打印 while True: time.sleep(1)if __name__ == "__main__": main()
文章评论